
What is Data Science/Product Fit And Why You Need It
I always felt that Data Science and Product Management share a lot of research aspects. When developing a new product, you have to work with assumptions, uncertainties, and gradually figure out a path to validate or verify these assumptions. You need to adapt till you have found something that solves a relevant problem for the customer. In essence, it is research.
On the other hand, I also frequently observe that this aspect is not sufficiently understood data science projects. Instead, we approach the project as if the main challenge is organizing a complex body of work in a way that can be planned out well with a high probability of success and a predictable deadline.
I’m aware that a large fraction of software engineering projects are also beyond pure execution. As the saying goes, software projects are always late and over budget. In his book “Inspired”, Marty Cagan introduces the concept of high-integrity commitment. In general he doesn’t believe it helps a lot to work with deadlines, but he admits there are situations when you need to know when something will be done, for example, in order to sync with other efforts like marketing for a new product launch.
He proposes that this kind of commitment should never be given on the spot, but there needs to be a discovery phase first where you try to reduce the uncertainty as much as possible before you commit.
Committing to a Data Science Project
Now I’m thinking, why shouldn’t we make this a general rule for any data science project? Way too often, I’ve been in planning meetings where the discussion goes like “so, can we put out a new model this quarter?” Data scientist (trying to avoid eye contact, probably trying to guesstimate over all the stuff they can’t say yet) “sure... . but let’s plan some time for the A/B test.” A better answer might have been “OK, but let us first take two weeks to lay down our assumptions and what we have and try to gather some data so I can get you a better estimate before we commit.”
In the product development process, people often talk about several “-ilities”:
- desirability - does anybody need or what this?
- feasiability - can we actually build this?
- viability - does it economically make sense to build this?
- usability - can we build it in a way that it can be used?
It is commonly understood (e.g. looking at Marty Cagan’s book, or “Testing Business Ideas” by Bland and Osterwalder) that in the early phases of product development, you should make your assumptions explicit and work to gather evidence to refute or verify these assumptions. Concepts like Product/Customer fit or Product/Market fit describe milestones you need to reach to have a product you can build a company around.
The Iterative Nature of Data Science Projects
I wish that amount of clarity would exist for data science projects as well. How do these ideas translate to a data science project? What are the most important types of uncertainty we should be thinking about?
Let’s go through a typical process with this diagram that I’m often using to illustrate the iterative nature of our work:
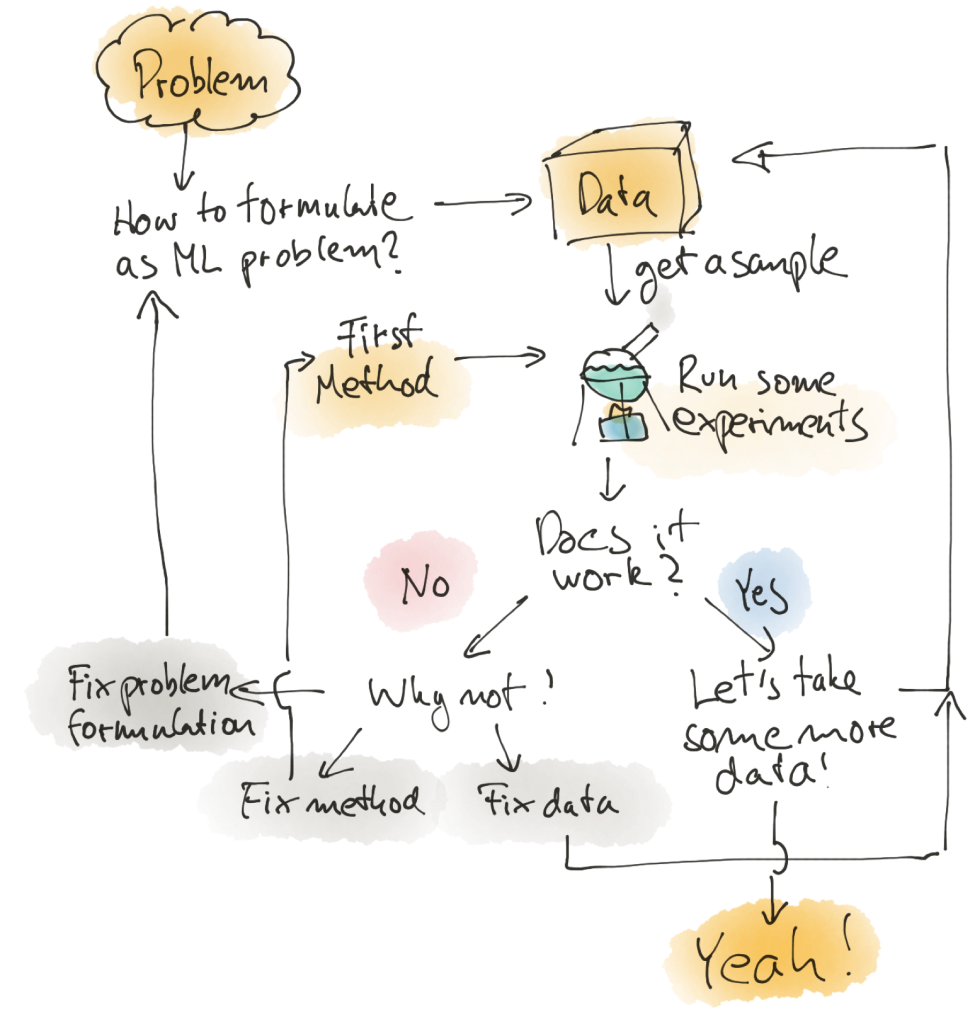
You start with some problem you want to solve with machine learning algorithms. The first step is to translate this problem into an ML problem. This might be quite straightforward, or it might actually be unclear if it hasn’t been done before.
For example, you want to compute recommendations (”show similar items that are relevant to this customer based on a item they are looking at.”) You might formulate this as a collaborative filtering problem (”compute similarities from interactions”), or as a click-prediction problem.
The next step is to get some initial data, a first potential algorithm, and train and evaluate a model. You then compare that to the expectations you’ve formulated when describing the customer problem how well the model should perform. If that looks good, congratulations, you can start adding more data, moving your pipelines to production, etc.
That’s of course pure fantasy, in most cases, it won’t work well and then you need to figure out why not. Is it the data? Is data missing, is data quality a problem? Does the data have the information and the signals we need to train a model? Is the learning algorithm any good? Do we need something more complex? Do we need something that’s more robust towards outliers? Or is the way we formulated the problem not right?
In any of these cases, you need to go back to the beginning and start iterating.
Achieving Data Science/Product Fit
I think we should another “fit” to our catalog when building data driven products. Let’s call it Data Science/Product fit.
I’ve thought about this a bit, but unlike with the other “-ilities”, achieving Data Science/Product fit cannot be so easily decomposed into different aspects, as data, problem formulation, and learning algorithm are all very closely intertwined.
Let’s call this learnability:
- You have turned your business/customer problem into an ML problem that solves the original problem. (This also includes ways to evaluate an ML solution against the original business problem, not just in the derived ML problem.)
- You have data to train a ML algorithm that works as required.
- You have an ML algorithm that works according to the evaluation criteria in the problem formulation.
Just like you need Product/Market fit, you need to achieve Data Science/Product fit before you should even think about building a production ML solution.
When Data Science Projects Fail
As I already said, these three aspects are very interrelated and it takes experience to figure out what is wrong when it does not work.
And a lot can go wrong:
- You might have no data.
- You might have data, but it is inconsistent and incorrect.
- You might have data of good quality, but the information you need is not in there.
- You might have the right data, but too little to represent all the complexity required to generalize well.
- You might have the right data, but the algorithm is too rigid / too sensitive to generalize well.
There are some hints. When someone else already solved a similar problem, there is a high chance your approach will work out once you have good data and adapted the approach the the specifics of your domain.
When to Know You’re Ready
Ultimately, you know you have attained Data Science/Product fit when you have attained learnability, which means you have a solid formulation for your problem, data, and a model that leads to good results evaluated on this data.
Depending on how novel the problem is you are trying to solve, this can be hard, but it is time (that should be timeboxed) well spent before you move into any kind of deadlines or execution plannings.
How do you deal with the uncertainty inherent in data science projects?